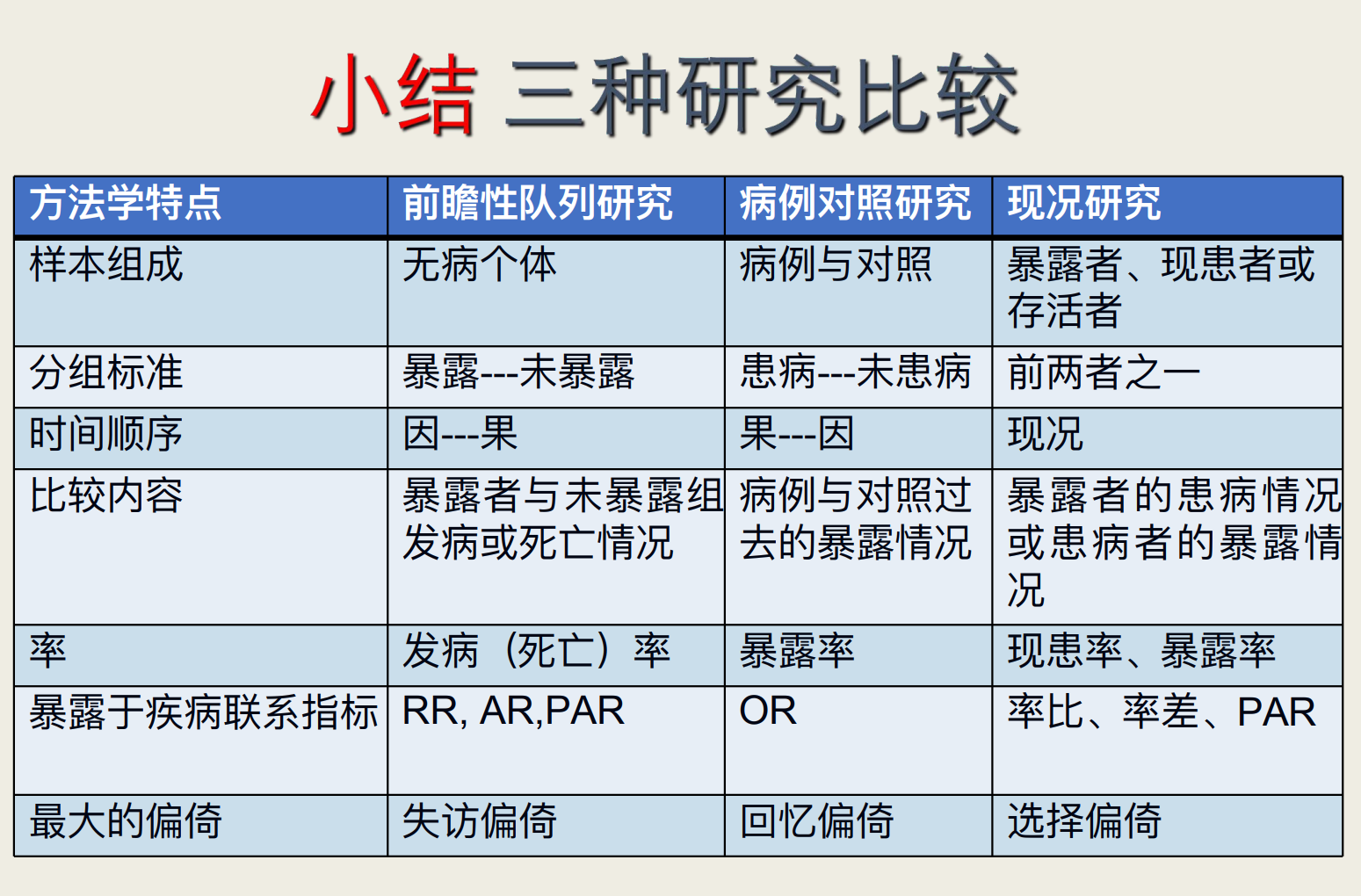
W4-病例对照研究
课程学习目标
- 理解病例对照研究的基本原理
- 区分辨别病例对照研究的研究类型
- 明确病例对照研究⽬的与⽤途
- 重述病例对照研究的研究设计与实施、资料的整理与分析
- 辨识及讨论病例对照研究中存在的偏倚及质量控制
- 了解样本⼤⼩的估计
- ⾃学病例对照研究的⼏种衍⽣类型
- 讨论⼏种匹配的原理与⽅法
- 分析OR值的计算⽅法及其流⾏病学意义
病例对照研究概述
基本原理
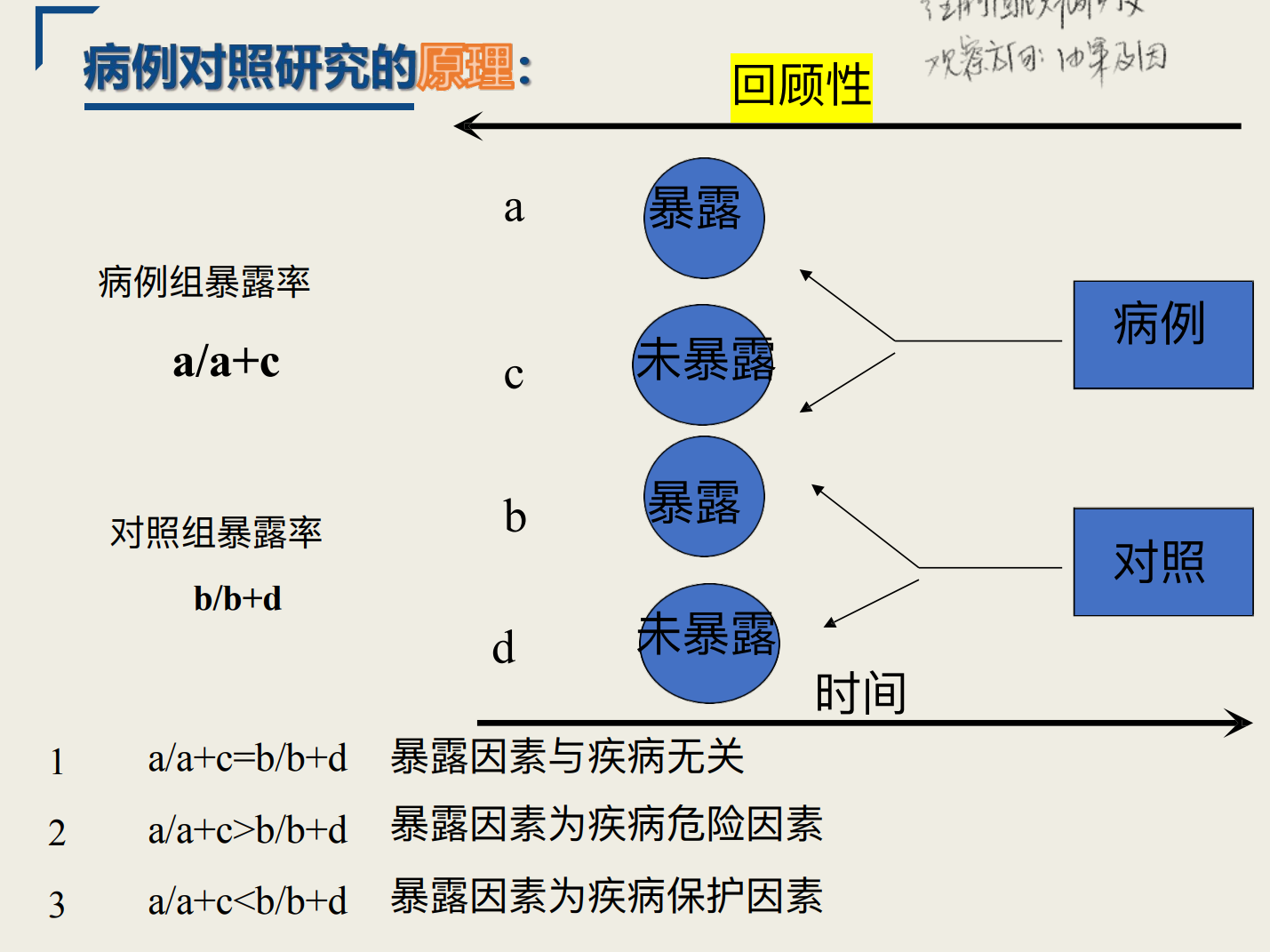
选定当前已经确诊的患某病的病例和未患该病且有可⽐性的对照,分别调查其既往暴露于某个(或某些)危险因⼦的情况及程度,采⽤统计学检验判断暴露危险因⼦与某病有⽆关联及其关联程度⼤⼩的⼀种观察研究⽅法
由果及因,分析型研究⽅法,检验假设
基本特点
1.属于观察性研究⽅法—⾮⼈为控制
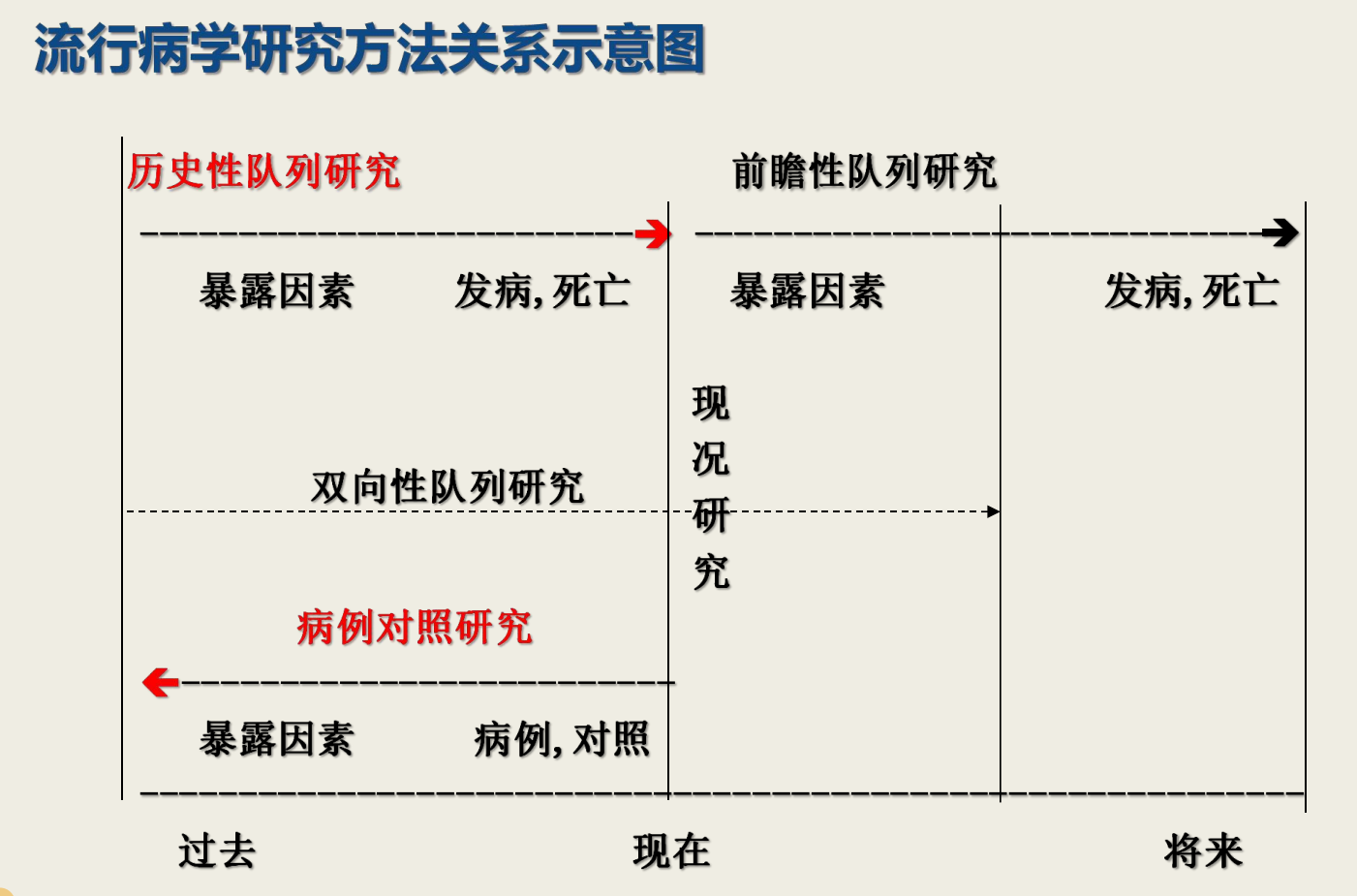
2.属于回顾性研究,观察⽅向由果及因
3.有对照:按研究时是否患病分为病例组和对照组
4.难以验证因果关系,因果关联的论证强度不如队列研究(存在回忆偏倚和混杂偏倚)
研究类型
1、非匹配病例对照研究:
case和control组分别抽⼈
对照选择⽆限制,但⼈数要⼤于case
⽆需成⽐例
2、匹配病例对照研究
按照匹配因素(混杂因素)平衡两组,从⽽排除⼲扰
3、衍生的几种主要研究类型
(1)巢式病例对照研究(nested case-control study)
• 队列研究的基础上设计⽽成
• 抽取观察期所有的发病⼈群作为case
• 在每个case发病时,在所有未发病者中,按照⼀些因素随机抽control,组成case-control , 并回忆以往的暴露史
• 这是matched case-control study
• 对照组全为未发病健康人群
(2)病例-队列研究(case-cohort study) (比巢式更好)
• 基线时的随机代表性样本-control
• 队列结束时全部病例-case
• 依然是病例对照研究
• 这⾥的对照组可以作为多种疾病结局的共⽤对照组(全部用这组)
(3)病例-病例研究(case-case study)
• 对照也是疾病组,可以是⼀种疾病的两个亚型,例如⻝管鳞癌和⻝管腺癌或两个基因型疾病的⽐较
• 适⽤于研究两组病因差别的部分,共同危险因素会被掩盖
(4)病例交叉研究(case crossover study)
• ⾃⼰与⾃⼰⽐,control为⾃⼰发病前的“时间段”
• 适⽤于研究暴露的瞬间效应,如⼀些突发事件的原因,如⼼肌梗死
• 需要:暴露在这两个时间段内是变化的
用途
1.⽤于疾病病因或危险因素的研究
潜伏期⻓及罕⻅病(直接找case组,比队列好)
初步形成病因假设
2.⽤于健康相关事件影响因素的研究
3.⽤于疾病预后因素的研究
筛选影响疾病预后的因素,将同⼀疾病的结局作为病例对照,追溯产⽣预后的因素,如治疗⽅式
4.⽤于临床疗效影响因素的研究
第二节 研究设计与实施
(1)确定研究目的
查阅相关⽂献资料,了解本课题的研究现状,结合既往的研究结果以及临床或卫⽣⼯作中需要解决的问题,提出病因假设,确定研究⽬的。
(2)明确研究类型
1.⾮匹配或频数匹配病例对照研究
-⽤于⼴泛地探索疾病的危险因素
2.个体匹配病例对照研究
-⽤于⼩样本研究或者因为病例的年龄、性别等构成特殊,随机抽取的对照组很难与病例组均衡可⽐
(一)病例与对照不匹配
(二)病例与对照匹配
• (成组/频数匹配病例对照研究)
频数匹配(⼜称成组匹配)
匹配因素所占的⽐例在对照组与病例组⼀致,
某项研究中按性别匹配,病例组男⼥各半,则对照组也是如此
• (个体匹配病例对照研究)

(3)确定研究对象
选择基本原则
1、代表性
• 病例能代表总体的病例
• 对照能代表产⽣病例的总体⼈群或源⼈群
2、可比性
• 两组主要特征⽅⾯⽆明显差异
1、病例选择
(1)病例的定义:诊断明确、统⼀,尽量使⽤⾦标准,如癌症的病理诊断,也可以限制⼀些性质
(2)病例的类型:新发病例、现患病例、死亡病例
首选新发病例!
优点:
代表性好
回忆偏倚⼩
病历资料容易获得
被调查因素改变少
缺点:
难以获得预期病例数,尤其是罕⻅病
现患病例对暴露回忆的可靠程度差,难以分辨暴露和疾病发⽣顺序
选择距离调查时间较短的先患病例
死亡病例由家属替代回答问题,准确性低
2、病例的来源
(1)医院来源的病例:
可节省费⽤,合作性好,资料容易得到,⽽且信息较完整、准确,但不同医院的病⼈代表性不同,仅从⼀个医院选择代表性较差
(2)社区人群来源的病例:
•可从疾病监测系统或居⺠健康档案系统中选择病例
•⾃然⼈群队列中选择病例
•优点:代表性好,结果推⼴性好
•缺点:调查⼯作⽐较困难,且耗费⼈⼒物⼒较多
3、如何选病例

同⼀或多个医疗机构中诊断的其他病例
优点:易于选择,⽐较合作,可以利⽤档案资料
缺点:暴露的⽔平⾼于原⼈群会产⽣选择偏倚
如何避免:1、因已知与研究的暴露因素有关的病种⼊院的病⼈不作为对照 2、选择尽可能多的病种的病⼈联合形成对照组
选择对照的方法


(4)确定样本量
亿堆方法,详见PPT
(大概不是很重要)
样本量计算注意事项:
• ⾸先,所估计的样本含量并⾮绝对精确的数值,因为样本含量的估计是有条件的,⽽这些条件并⾮是⼀成不变的。
• 其次,应当纠正样本量越⼤越好的错误看法。样本量过⼤,常会影响调查⼯作的质量,增加负担、费⽤。
(5)确定研究因素
根据研究⽬的,确定研究因素(或暴露),尽可能采取国际或国内统⼀标准来定义和确定暴露与否或暴露⽔平,便于交流。
每种酒的酒精含量, BMI的分级
可以从暴露的数量和暴露持续时间评价暴露⽔平。
对于发病时间窗⼝较⻓的疾病如肿瘤,关注各种不同时间下的暴露或暴露的累积量
测量指标尽量选⽤定量或半定量指标,也可按明确的标准进⾏定性测定。由细到粗分类
研究因素应以满⾜研究⽬的的需要为原则,即与研究⽬的有关的变量不可缺少且尽量细致,与研究⽬的⽆关的内容则不要列⼊。
(6)资料收集方法
资料来源:
询问调查对象及填写问卷
查阅档案:疾病和死亡登记、医疗档案
现场实际测量某些指标:⽣物学指标、体格测量
收集资料过程要注意:
■ 资料的收集在病例对照研究中⼗分重要,⽅式⽅法不恰当,收集的资料就不可靠,会产⽣统计处理⽆法纠正的系统误差。
■ 质量控制:调查员培训、监督和检查整个过程减少测量偏倚、 收集后核查等
■ 保证病例和对照的信息收集是采⽤类似的⽅式⽅法(包括收集⽅式、资料来原、暴露测量⽅式等)
第三节 资料的整理与分析
(一)资料的整理
1.对所收集的原始资料进⾏全⾯检查与核实,确保准确和完整性。 2.对原始资料进⾏分组、归纳或编码后输⼊计算机,建⽴数据库。
(二)资料的分析
1、描述性统计:
(1)⼀般特征描述(年龄、性别、疾病类型)
(2)均衡性检验:比较病例组和对照组在研究因素以外其它主要特征有否可比性。两组间非研究因素均衡可比,才能认为两组暴露率差异与发病有关。
• 两组间⾮研究因素均衡可⽐,才能认为两组暴露率差异与发病有关
• 否则要在统计学模型中调整这些变量
2、推断性分析
(详见PPT,懒了~)(大抵可能应该...不重要吧?)
(1)⾮匹配设计资料的分析
先归纳
进行关联性分析
关联强度分析(OR值)
(2)1:1配对资料的分析
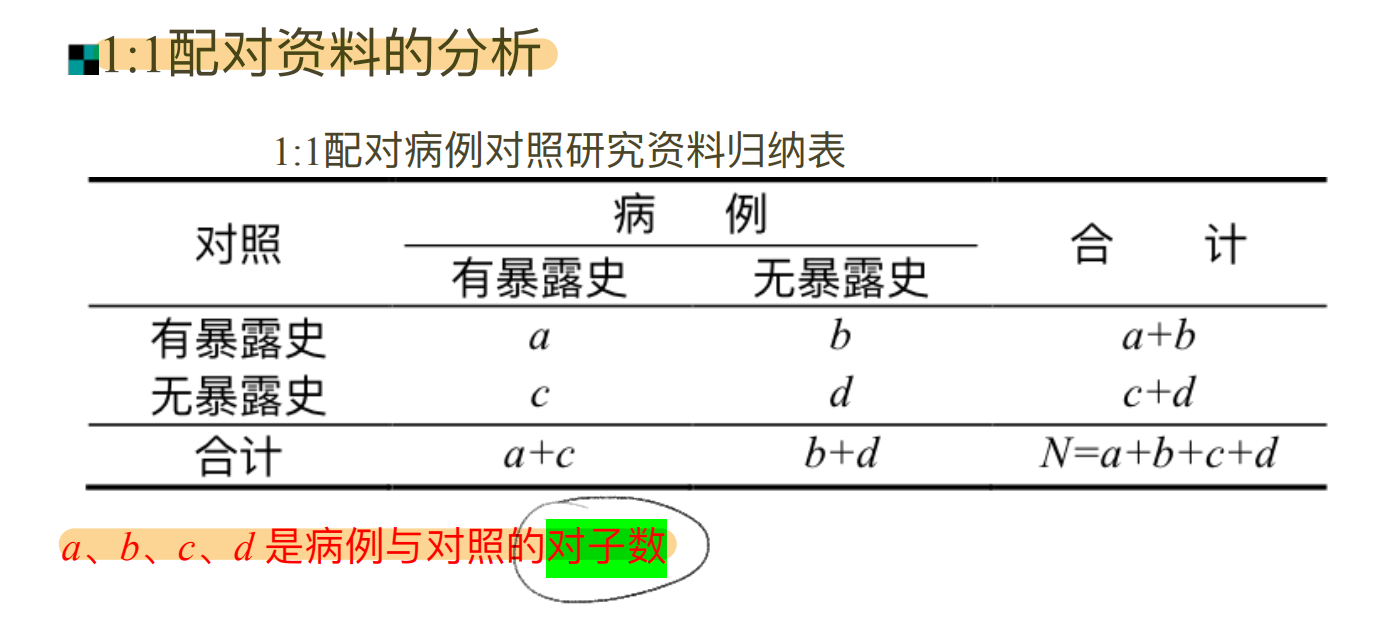

(3)⾮匹配资料的分层分析

(4)剂量反应关系的分析
当获得的某些暴露因素为不同暴露⽔平时,该资料为分级资料;
将不同暴露⽔平分成多个有序的暴露等级,不同暴露等级与⽆暴露或最低⽔平的暴露作⽐较,分析暴露与疾病之间的剂量反应关系。
(复习时建议还是看一遍PPT)
第四节 偏倚及其控制
一、偏倚
(一)选择偏倚
(队列研究中有讲过)
产⽣原因:选择的研究对象不能代表源⼈群
常见偏倚:
⼊院率偏倚(伯克森偏倚,Berkson’s bias)
选择医院的病⼈作为病例与对照,由于病⼈对医院的选择或者医院对病⼈的选择,导致病⼈与对照不代表⽬标⼈群;
解决:尽可能采⽤⼀段时间多个医院的全部病例以及与病例相同的多个医院的⼈群中选择对照。
现患病例-新发病例偏倚(奈曼偏倚,Neyman bias)
现患病例会导致得到的暴露信息只与存活有关,未必与发病相关或是已经被改变。
解决⽅案:选择incident cases!
检出症候偏倚(暴露偏倚,unmasking bias)
某因素的存在容易出现⼀些症状,因⽽提⾼所研究疾病早期病例的检出率,使得关联性被⾼估。
解决:选择各种分期的cases。
(二)信息偏倚/测量偏倚
产⽣原因: 收集整理信息中测量暴露与结局的⽅法有缺陷
常见偏倚:
回忆偏倚(recall bias)
病例对照中最常⻅的信息偏倚,研究对象对暴露史或既往史回忆的准确性和完整性存在系统误差。与时间间隔⻓短和事件重要程度有关。
解决:利⽤客观资料、有调查技巧帮助回忆
调查偏倚(investigation bias)--来⾃调查者或调查对象
对于case和control采⽤不同的询问⽅式或测量⽅法不⼀致等产⽣偏倚, 需做好调查员的培训,使⽤仪器前要矫正
(三)混杂偏倚(confounding bias)
(由于第三个变量导致的关联)
当研究暴露于某因素与某疾病关系时,由于⼀个或多个既与疾病有关系⼜与暴露因素密切相关的外部因素的⼲扰,导致掩盖或夸⼤了所研究的暴露因素与该疾病的联系,该外来因素叫混杂因素(confounding factor),造成的偏倚叫混杂偏倚
如吸烟肺癌研究:年龄有可能是混杂
解决办法:限制、匹配、分层分析或调整
第五节 与队列研究优点与局限性比较
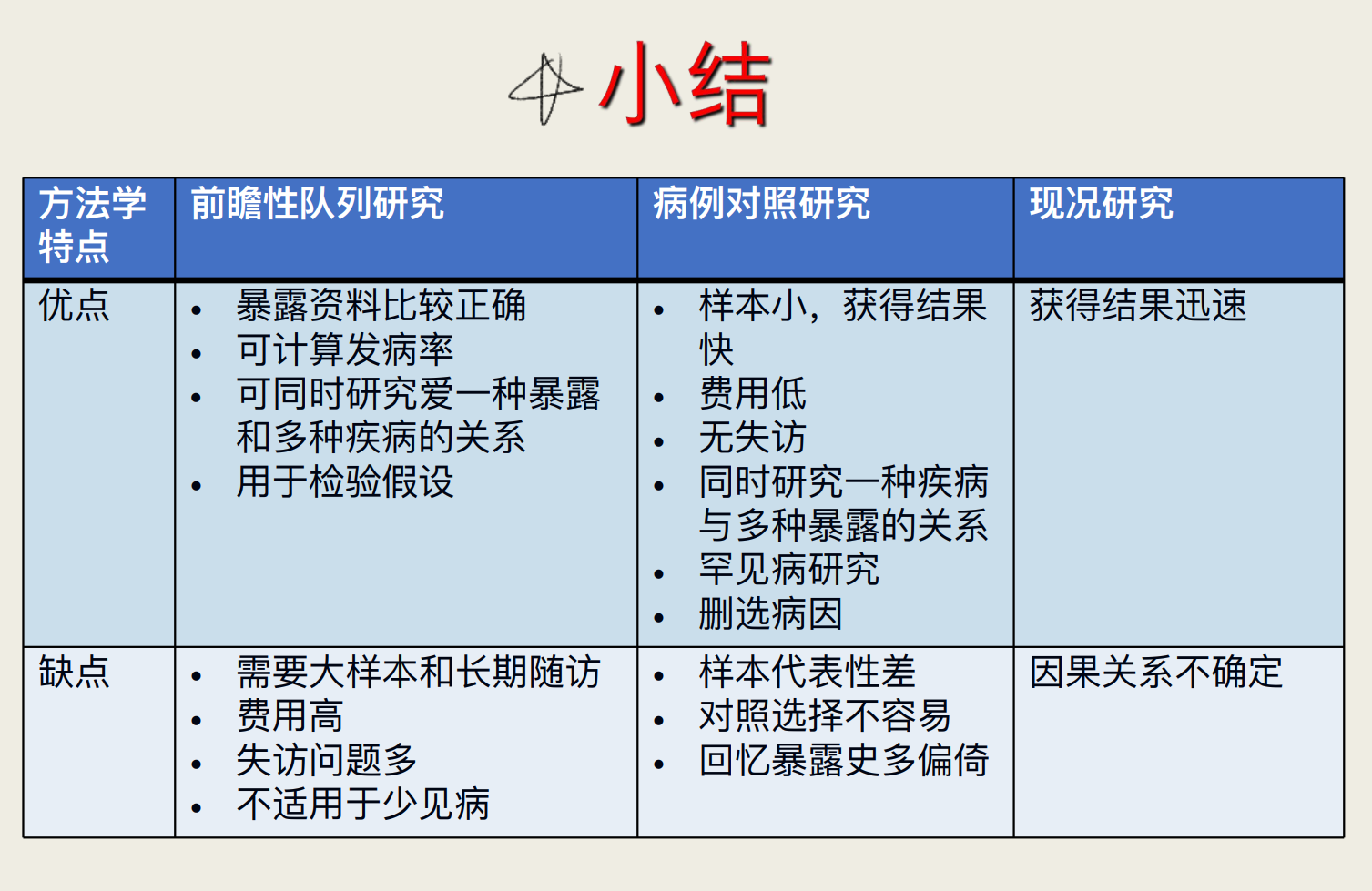
(一)病例对照研究的优点
1、特别适⽤于罕⻅病、潜伏期⻓疾病的病因研究
2、省⼒、省钱、省时间,并易于组织实施
3、可同时研究多个因素(暴露)与某种疾病的联系
4、应⽤范围⼴,不仅应⽤于病因的探讨,⽽且⼴泛应⽤于其他健康事件的原因分析
(二)病例对照研究的缺点
1、不适于研究暴露⽐例很低的因素 (和队列相反)
2、选择偏倚难以避免
3、获取既往信息时,难以避免回忆偏倚
4、暴露与疾病时间先后难以判断,论证因果关系的能⼒较弱(比队列弱)
5、不能测定暴露组和⾮暴露组的发病率,不能直接分析RR,只能⽤OR 来估计RR
(以下图片前面章节也有出现)